

理论部分
不使用数据库连接池
我们先来看看普通的Mysql的连接过程,下图是我抓包分析的在端口3306的数据包: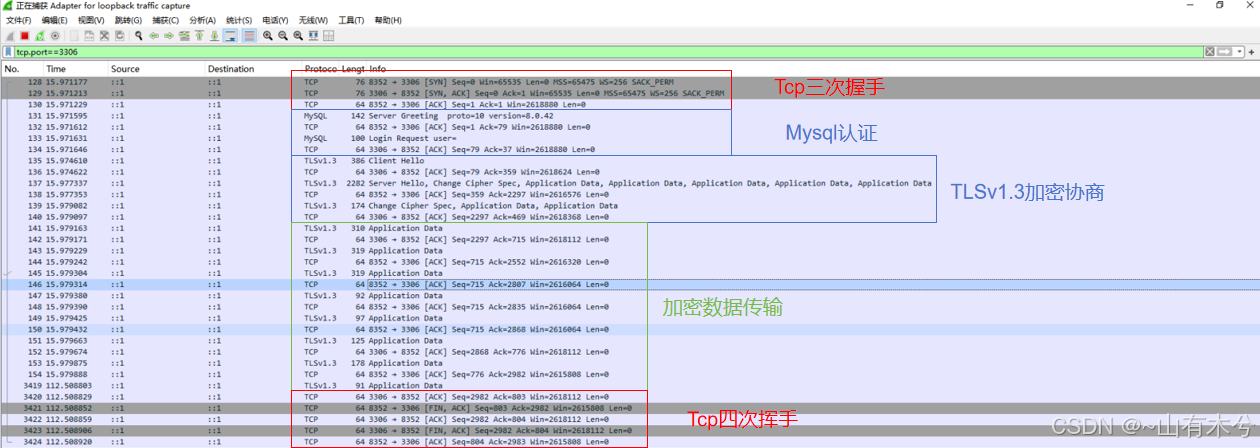
在执行Mysql命令之前,需要先经过Tcp的三次握手、Mysql的认证服务,TLS加密服务等操作;
下图来自数据库连接池学习笔记(一):原理介绍+常用连接池介绍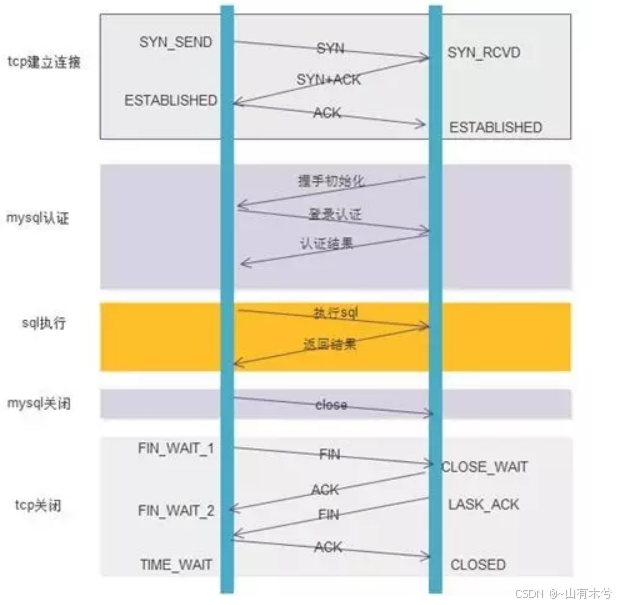
经过上述分析,我们知道,如果不使用数据库连接池,执行单条Mysql命令会多了非常多我们不关心的网络交互。
如果执行的Mysql查询命令比较多,就会严重影响性能。
不使用数据库连接池:
优点: 实现简单
缺点: 网络IO较多
数据库的负载较高
响应时间较长及QPS较低
应用频繁的创建连接和关闭连接,导致临时对象较多
在关闭连接后,会出现大量TIME_WAIT 的TCP状态(在2个MSL之后关闭)
使用数据库连接池
初始连接建立
当应用程序第一次访问数据库时,需要完成以下步骤:
- 系统会创建一个新的数据库连接
- 这个连接需要经过身份验证(用户名/密码验证)
- 建立TCP/IP网络连接
- 初始化会话参数和设置
连接复用机制
在后续访问中:
- 系统会从连接池中获取先前建立的可用连接
- 直接使用该连接执行SQL语句(如SELECT, INSERT, UPDATE等)
- 执行过程中无需重新进行身份验证和连接建立
- 典型的复用场景包括:
- 用户多次查询同一数据表
- 处理事务中的多个SQL操作
- 执行批量数据处理任务
连接回收过程
每次查询完成后:
- 系统会将连接标记为”空闲”状态
- 连接会被归还到连接池中
- 连接保持开启状态,等待下次请求
- 如果连接空闲时间超过配置的阈值(如30分钟),可能会被自动关闭
这种机制显著提高了性能,减少了频繁创建和销毁连接的开销。
常见的几种资源池
在实际应用中,由于创建和销毁系统资源(如连接、内存块、线程等)的成本往往远高于使用资源的成本,因此通常会引入资源池的概念来提高系统性能。这种技术通过预先创建并维护一组可重用资源,避免了频繁的资源初始化和销毁操作,从而显著提升系统效率。
常见的资源池包括以下几种类型:
内存池:
- 在C++程序开发中,malloc通过brk()系统调用向操作系统申请内存时,会一次性申请较大的内存块(只是通过brk方式申请的内存会维护内存池,小块内存;通过nmap方式申请的大块内存(默认是大于128k)没有内存池,是直接归还给操作系统了)
- 当使用free释放内存时,这些内存并不会立即归还给操作系统,而是被缓存在malloc维护的内存池中
- 当下次程序再次申请内存时,malloc会优先从内存池中分配可用内存块
- 例如:当程序频繁进行小内存块的分配和释放时,内存池可以避免频繁的系统调用,提高内存分配效率
线程池:
- 传统的线程创建和销毁涉及操作系统层面的资源分配和回收,开销较大
- 线程池通过预先创建一组线程并保持活跃状态,等待任务分配
- 主要优势包括:
- 线程复用:避免频繁创建销毁线程的开销
- 任务解耦:将任务提交与执行分离,提高系统灵活性
- 资源管理:可以限制并发线程数量,防止系统过载
- 应用场景:Web服务器处理请求、批量数据处理等需要高并发的场景
数据库连接池:
- 建立数据库连接涉及网络通信、身份验证等耗时操作
- 连接池维护一组已建立的数据库连接,应用程序使用时直接从池中获取
- 使用完毕后连接归还池中而非关闭,供其他请求复用
- 典型配置参数包括:最小连接数、最大连接数、连接超时时间等
- 优势:显著降低连接建立开销,提高数据库访问效率
这些资源池技术在现代软件系统中被广泛应用,特别是在高并发、高性能要求的场景下,合理配置资源池可以大幅提升系统整体性能。在实际应用中,由于创建和销毁系统资源(如连接、内存块、线程等)的成本往往远高于使用资源的成本,因此通常会引入资源池的概念来提高系统性能。这种技术通过预先创建并维护一组可重用资源,避免了频繁的资源初始化和销毁操作,从而显著提升系统效率。
代码实现
本项目数据库连接池实现了三个核心类:
DbConnection:管理单个数据库连接DbConnectionPool:管理数据库连接池MysqlUtil:提供便捷的数据库操作接口
以下就分别来了解一下这几个类的实现。
DbConnection类实现
成员变量:
std::shared_ptr<sql::Connection> conn_数据库连接std::string host_数据库主机地址,如tcp://127.0.0.1:3306std::string user_用户名std::string password_密码std::string database_使用数据库std::mutex mutex_互斥锁
成员方法:
DbConnection()构造函数, 创建并初始化数据库连接,设置连接属性(这里是设置的单语句执行,防止SQL的注入)~DbConnection()析构函数,自动清理连接资源,调用cleanup()函数ping()函数,使用简单的SELECT 1语句检测与数据库的通信是否正常isValid()函数,与ping函数类似,区别在于不在意查询结果,遇到异常返回falsereconnect()函数,尝试重新建立数据库连接cleanup()函数,清理连接状态,需要确保所有事务以及完成,并且消费完所有查询结果bindParams(),绑定参数executeQuery()函数,执行sql语句的查询,并返回查询结果executeUpdate()函数,执行sql语句的更新操作
在上述函数中比较重要的就是executeQuery()和executeUpdate()函数,以下是其代码定义与注释
executeQuery()函数
1 | template<typename... Args> //可变参数模板,接受任意数量、任意类型的参数 |
这个是执行Sql查询的操作,在上层,通过代码
1 | std::string sql = "SELECT id FROM users WHERE username = ? AND password = ?"; |
传入了sql语句:”SELECT id FROM users WHERE username = ? AND password = ?”
以及两个参数:username=”user1“和password=”123456“;
通过参数绑定后,完整的sql语句就是
“SELECT id FROM users WHERE username = user1 AND password =123456”
随后执行Mysql的语句查询,返回查询到的结果。
executeUpdate函数
1 | template<typename... Args> |
示例语句:
1 | const std::string sql = "INSERT INTO video_stats (video_name, view_count, like_count) VALUES (?, 0, 0) ON DUPLICATE KEY UPDATE video_name=video_name"; |
SQL注入的理解:
当用户登录网站时,通常会输入用户名和密码。
以下是一段正常的 SQL 查询代码:
1 | SELECT * FROM users WHERE username = 'user1' AND password = 'password1'; |
如果攻击者输入:
1 | 用户名: admin' -- |
SQL查询变成:
1 | SELECT * FROM users WHERE username = 'admin' --' AND password = 'anything'; |
其中 – 是 SQL 的注释符号,忽略了密码条件,直接绕过了身份验证。
更多可以参考
SQL 注入
DbConnectionPool类实现
成员变量:
std::string host_; 连接数据库的主机名std::string user_;用户名std::string password_;密码std::string database_;指定使用的数据库std::queue<std::shared_ptr<DbConnection>> connections_;数据库连接池std::mutex mutex_;互斥锁std::condition_variable cv_;条件变量bool initialized_ = false;初始化标识,确保仅初始化一次std::thread checkThread_;// 添加检查线程,检测数据库连接池的连接健康状况
成员方法:
使用单例模式,
init()函数,初始化线程池,创建 poolSize 个 DbConnection 对象,放入队列DbConnectionPool()构造函数,创建并分离后台线程,定期检查连接可用性~DbConnectionPool()析构函数,清空连接队列,释放所有连接资源getConnection()函数,从连接池获取一个可用连接createConnection()函数,创建一个新的数据库连接checkConnections(),后台线程,定期检查所有连接是否可用。
这里比较重要的就是getConnection() 函数,我贴出来代码
1 | std::shared_ptr<DbConnection> DbConnectionPool::getConnection() |
函数的核心逻辑为:
- 如果连接池为空,则阻塞等待(使用条件变量)
- 连接池始终返回
std::shared_ptr<DbConnection> - 通过自定义的deleter在用户使用完数据库某条连接后自动归还给池
使用lambda表达式,当conn使用完成后,将其归还到connections_池中去。
1 | // 使用自定义 deleter: |
MysqlUtil类实现
1 | static void init(const std::string& host, const std::string& user, |
MysqlUtil类的实现比较简单,提供了对数据库的简单接口,隐藏了底层连接池的复杂性。主要是提供了三个方法,分别是数据库连接池的初始化、从连接池中获取连接以执行查询操作和更新(增删改)操作。MysqlUtil作为一个便捷的工具类,简化了调用接口,让业务层可以更轻松的使用连接池进行增删改查的工作。
以上就是我对数据库连接池的一些理解,如有不当之处,敬请指出。