这一篇文章是基于项目LITEHUB分析的关于HTTP的请求和响应篇章,后续将仔细分析这个项目所涉及到的知识点。
![image]()
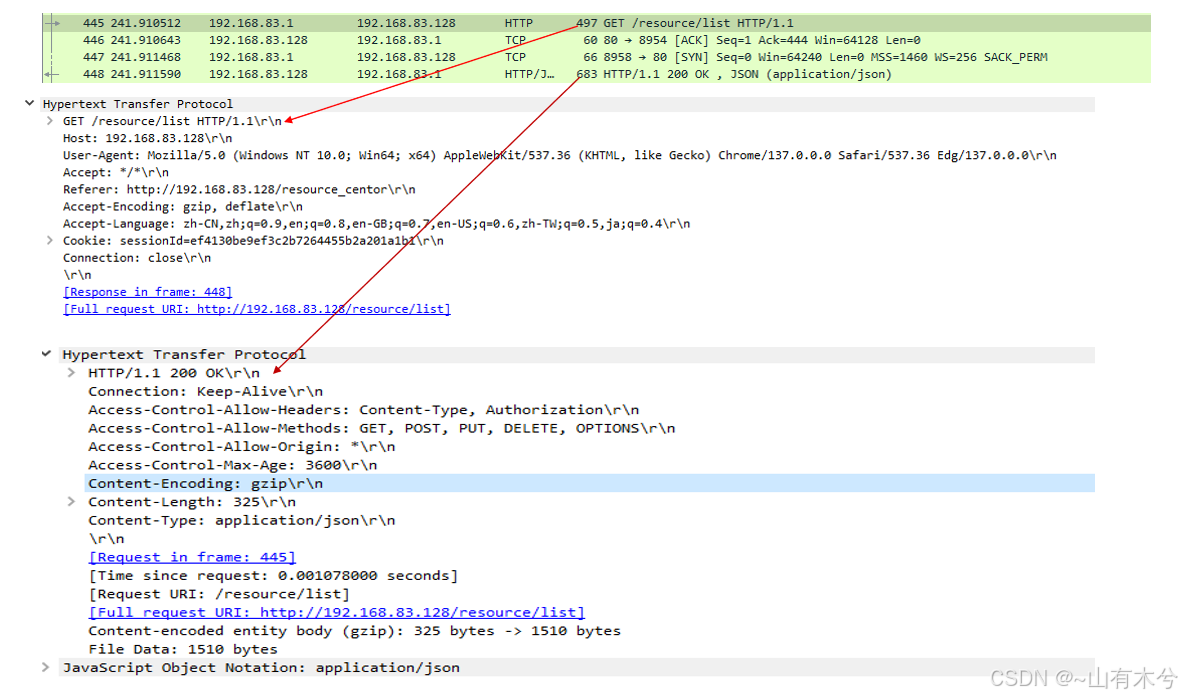
上图是使用wireshark抓包分析的HTTP刷新网页的请求以及返回的响应报文格式。接下来我们就详细分析:
请求报文
理论部分
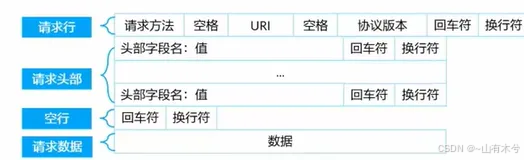
请求报文主要由请求行、请求头、空行、请求头构成。
![image]()
请求行包括一下字段:常见的方法包括GET(请求信息)、POST(提交数据,表单)方法等,资源路径(请求资源的URI路径)、HTTP的版本(HTTP1.1/HTTP2.0)
请求头的字段较多,常使用的包含以下几个:
● Host:请求的服务器的域名。
● Accept:客户端能够处理的媒体类型。
● Accept-Encoding:客户端能够解码的内容编码。
● Authorization:用于认证的凭证信息,比如token数据。
● Content-Length:请求体的长度。
● Content-Type:请求体的媒体类型。
● Cookie:存储在客户端的cookie数据,在我的项目中,也是通过存在cookie字段来区别不同用户。
空行是请求头部和请求主体之间的空行,用于分隔请求头部和请求主体。
而请求体通常用于 POST 和 PUT 请求,包含发送给服务器的数据。
wireshark抓包分析
![image]()
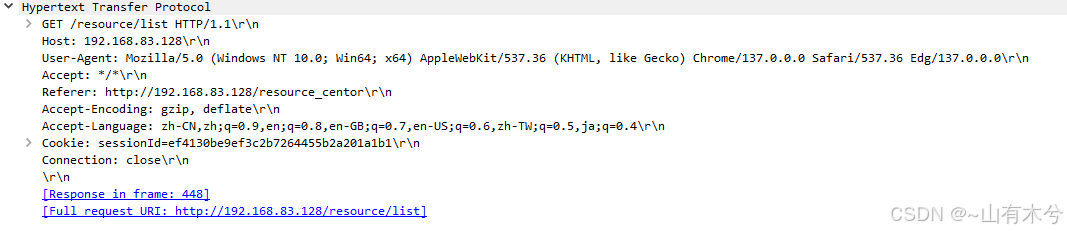
- 请求行:这里使用请求方法为
GET,请求的路径为/resource/list(服务器通过路由转发确定其实际请求的路径资源,后面会分析),并且使用的版本号是HTTP/1.1.
- 请求头:是以一系列的键值对组成的。如上图包括
Host:192.168.83.128(表示请求的服务器的域名,这个字段是为了区分在一个服务器上存在多个地址的问题,如百度和edge都在一台服务器的不同网卡上服务,通过这个字段可以区分);Cookie: sessionId=ef4130be9ef3c2b7264455b2a201a1b1(保持访问的一个状态),其余字段感兴趣的话可以自己去了解
- 空行:
\r\n,用于分割请求头和请求体;
- 请求体:这里为空;
代码解析
上面我们已经分析了请求体的格式,接下来我们就根据格式,通过代码解析请求报文。
在HttpContext.h中定义解析的状态,只有当前状态成功解析完成后,才可以转到下一个状态;
1
2
3
4
5
6
7
| enum HttpRequestParseState
{
kExpectRequestLine,
kExpectHeaders,
kExpectBody,
kGotAll,
};
|
在HttpContext.c中定义两个标志,用于标志每个状态解析是否出错以及是否解析完成(如果请求体有值,就需要解析到请求体;如果请求体为空,则解析到空行就行)。
1
2
| bool ok = true;
bool hasMore = true;
|
1.请求行解析
当前的请求行是这样:GET /resource/list HTTP/1.1\r\n
请看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
| if (state_ == kExpectRequestLine)
{
const char *crlf = buf->findCRLF();
if (crlf)
{
ok = processRequestLine(buf->peek(), crlf);
if (ok)
{
request_.setReceiveTime(receiveTime);
buf->retrieveUntil(crlf + 2);
state_ = kExpectHeaders;
}
else
{
hasMore = false;
}
}
else
{
hasMore = false;
}
}
bool HttpContext::processRequestLine(const char *begin, const char *end)
{
bool succeed = false;
const char *start = begin;
const char *space = std::find(start, end, ' ');
if (space != end && request_.setMethod(start, space))
{
start = space + 1;
space = std::find(start, end, ' ');
if (space != end)
{
const char *argumentStart = std::find(start, space, '?');
if (argumentStart != space)
{
request_.setPath(start, argumentStart);
request_.setQueryParameters(argumentStart + 1, space);
}
else
{
request_.setPath(start, space);
}
start = space + 1;
succeed = ((end - start == 8) && std::equal(start, end - 1, "HTTP/1."));
if (succeed)
{
if (*(end - 1) == '1')
{
request_.setVersion("HTTP/1.1");
}
else if (*(end - 1) == '0')
{
request_.setVersion("HTTP/1.0");
}
else
{
succeed = false;
}
}
}
}
return succeed;
}
void HttpRequest::setQueryParameters(const char *start, const char *end)
{
std::string argumentStr(start, end);
std::string::size_type pos = 0;
std::string::size_type prev = 0;
while ((pos = argumentStr.find('&', prev)) != std::string::npos)
{
std::string pair = argumentStr.substr(prev, pos - prev);
std::string::size_type equalPos = pair.find('=');
if (equalPos != std::string::npos)
{
std::string key = pair.substr(0, equalPos);
std::string value = pair.substr(equalPos + 1);
queryParameters_[key] = value;
}
prev = pos + 1;
}
std::string lastPair = argumentStr.substr(prev);
std::string::size_type equalPos = lastPair.find('=');
if (equalPos != std::string::npos)
{
std::string key = lastPair.substr(0, equalPos);
std::string value = lastPair.substr(equalPos + 1);
queryParameters_[key] = value;
}
}
|
根据上述函数,我们就解析出来了请求行的三个字段,请求方法、url路径、以及Http的版本号。接下来就开始解析请求头了。
2.请求头解析
根据上述分析,请求头是以键值对形式存储的(每一行存储一个键值对),并且键和值的分割是以“:”分割,基于这个分析,请求头就比较好解析了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| else if (state_ == kExpectHeaders)
{
const char *crlf = buf->findCRLF();
if (crlf)
{
const char *colon = std::find(buf->peek(), crlf, ':');
if (colon < crlf)
{
request_.addHeader(buf->peek(), colon, crlf);
}
else if (buf->peek() == crlf)
{
if (request_.method() == HttpRequest::kPost ||
request_.method() == HttpRequest::kPut)
{
std::string contentLength = request_.getHeader("Content-Length");
if (!contentLength.empty())
{
request_.setContentLength(std::stoi(contentLength));
if (request_.contentLength() > 0)
{
state_ = kExpectBody;
}
else
{
state_ = kGotAll;
hasMore = false;
}
}
else
{
ok = false;
hasMore = false;
}
}
else
{
state_ = kGotAll;
hasMore = false;
}
}
else
{
ok = false;
hasMore = false;
}
buf->retrieveUntil(crlf + 2);
}
else
{
hasMore = false;
}
}
void HttpRequest::addHeader(const char *start, const char *colon, const char *end)
{
std::string key(start, colon);
++colon;
while (colon < end && isspace(*colon))
{
++colon;
}
std::string value(colon, end);
while (!value.empty() && isspace(value[value.size() - 1]))
{
value.resize(value.size() - 1);
}
headers_[key] = value;
}
|
在找到空行后,需要根据请求方法(判断是否是POST或者PUT方法)和Content-Length判断是否需要继续读取body;如果不需要,则直接退出解析;如果请求体有数据,开始解析请求体。
3.请求体的解析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
| else if (state_ == kExpectBody)
{
if (buf->readableBytes() < request_.contentLength())
{
hasMore = false;
return true;
}
const std::string &contentType = request_.getHeader("Content-Type");
if (contentType.find("multipart/form-data") != std::string::npos)
{
ok=parseMultipartData(buf);
request_.set_parseMultipartData_state(ok);
LOG_INFO<<"multipart/form-data解析"<<((ok)?"成功":"失败");
state_ = kGotAll;
hasMore = false;
}
else
{
std::string body(buf->peek(), buf->peek() + request_.contentLength());
request_.setBody(body);
buf->retrieve(request_.contentLength());
state_ = kGotAll;
hasMore = false;
}
}
bool HttpContext::parseMultipartData(Buffer *buf)
{
const char* crlf = buf->findCRLF();
if (!crlf) return false;
std::string boundary(buf->peek(),crlf);
LOG_INFO<<"boundary:"<<boundary;
buf->retrieveUntil(crlf + 2);
crlf = buf->findCRLF();
if (!crlf) return false;
std::string dispositionLine(buf->peek(), crlf);
buf->retrieveUntil(crlf + 2);
std::string Content_Disposition;
std::string name;
std::string filename;
size_t Content_Pos = dispositionLine.find("Content-Disposition:");
if (Content_Pos != std::string::npos)
{
Content_Pos += 20;
size_t ContentEnd = dispositionLine.find('"', Content_Pos);
if (ContentEnd != std::string::npos)
Content_Disposition.assign(dispositionLine.data() + Content_Pos, ContentEnd - Content_Pos);
}
LOG_INFO<<"Content_Disposition:"<<Content_Disposition;
size_t namePos = dispositionLine.find("name=\"");
if (namePos != std::string::npos)
{
namePos += 6;
size_t nameEnd = dispositionLine.find('"', namePos);
if (nameEnd != std::string::npos)
name.assign(dispositionLine.data() + namePos, nameEnd - namePos);
}
LOG_INFO<<"name:"<<name;
size_t filePos = dispositionLine.find("filename=\"");
if (filePos != std::string::npos)
{
filePos += 10;
size_t fileEnd = dispositionLine.find('"', filePos);
if (fileEnd != std::string::npos)
filename.assign(dispositionLine.data() + filePos, fileEnd - filePos);
}
LOG_INFO<<"filename:"<<filename;
crlf = buf->findCRLF();
if (!crlf) return false;
buf->retrieveUntil(crlf + 2);
crlf = buf->findCRLF();
if (!crlf) return false;
buf->retrieveUntil(crlf + 2);
const char* fileStart = buf->peek();
const char* fileEnd = std::search(
fileStart, buf->peek()+ buf->readableBytes(),
boundary.c_str(), boundary.c_str() + boundary.size()
);
if (fileEnd == buf->beginWrite()) {
return false;
}
LOG_INFO<<"开始创建文件咯";
request_.set_filename(filename);
if (filename.find(".avi")!= std::string::npos ||filename.find(".mp4")!= std::string::npos||filename.find(".mkv")!= std::string::npos)
{
FileUtil writer("/root/uploads/videos/" + filename);
writer.writeBinary(fileStart, fileEnd - fileStart);
LOG_INFO<<"这是一个视频"<<filename;
}
else
{
FileUtil writer("/root/uploads/" + filename);
writer.writeBinary(fileStart, fileEnd - fileStart);
}
LOG_INFO<<"创建完成";
buf->retrieveUntil(fileEnd+2);
return true;
}
|
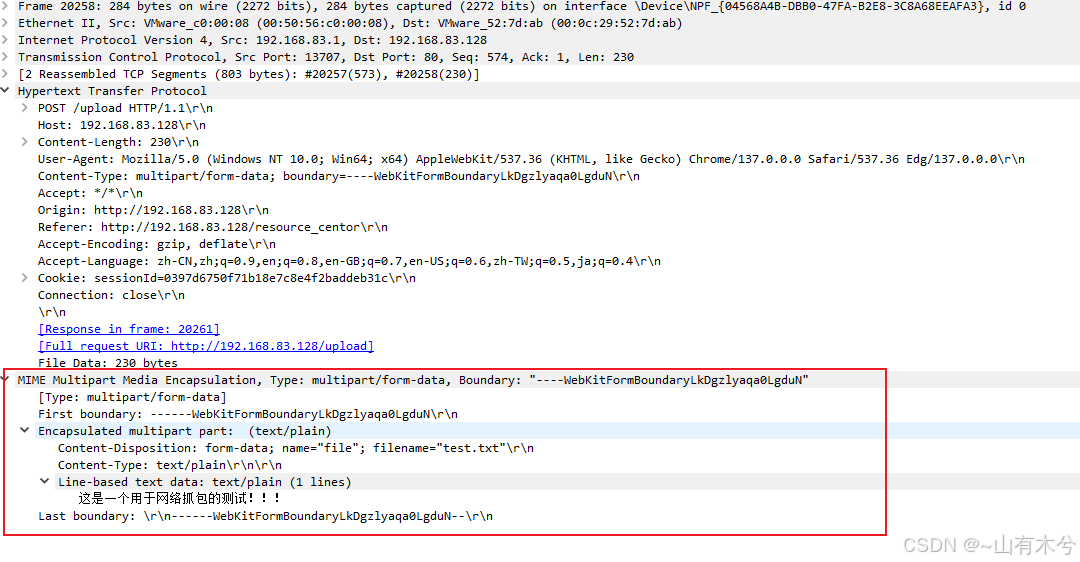
上面的抓包过程中没有文件上传的解析,这里我上传了一个txt文件,并抓包分析。
![image]()
上图的红框部分就是我此次上传的txt文件的请求体部分的抓包。以下是分析:
- 边界值:——WebKitFormBoundaryLkDgzlyaqa0LgduN(细心的同学看到了,在请求体中的最开始部分和结尾部分都是以这个值作为分界线的,而在这直接的就是具体的内容)
- Content-Disposition: form-data; name=”file”; filename=”test.txt”;form-data表示是一个表单数据;name字段对应表单中的字段名;filename是客户端上传的一个原始文件名。这个字段是用于告知服务器如何处理这部分数据。
- Content-Type: text/plain\r\n\r\n。这个是声明这部分数据的媒体类型。(text/plain表示内容是无格式的纯文本)
![image]()
这部分就是实际的传输内容。
传输如视频或者压缩文件为01二进制流。所以对于上传不同媒体数据的思想是,通过Content-Disposition中的filename字段,获取原数据的文件名,保存为相应的文件类型,并将实际的内容放到对应的文件中。
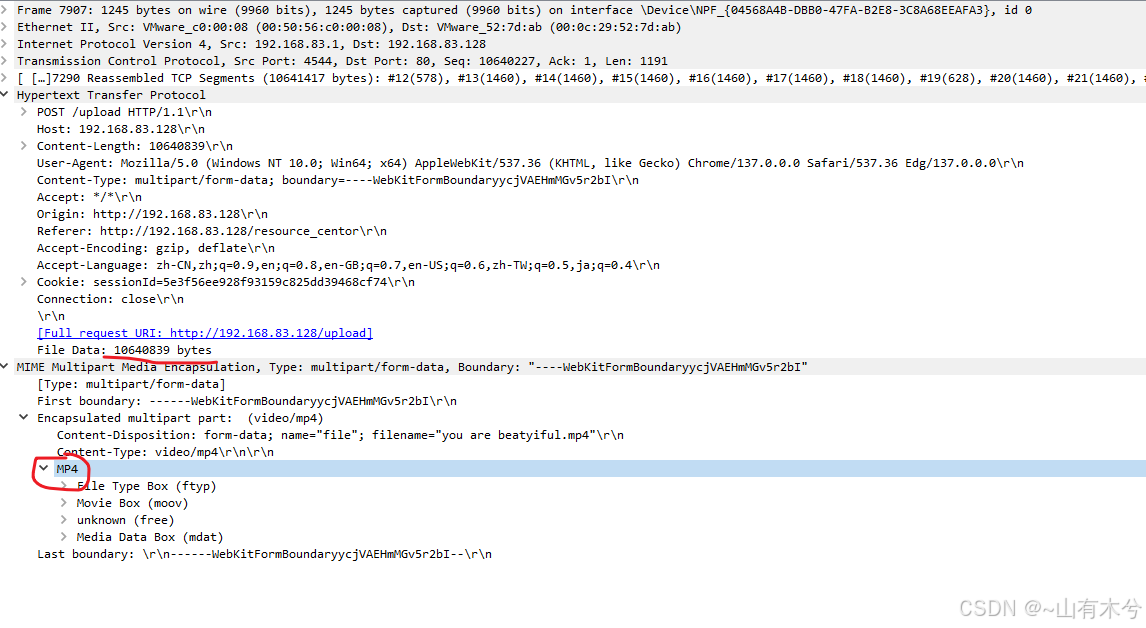
视频上传的抓包截图:
![image]()
响应报文
理论部分
![image]()
HTTP响应报文是服务器向客户端返回的数据格式,用于传达服务器对客户端请求的处理结果以及相关的数据。一个标准的HTTP响应报文通常包含状态行、响应头、空行、响应体。
状态行包含HTTP版本、状态码和状态消息。例如:HTTP/1.1 200 OK,404表示没有找到,429表示请求连接过多,我的羡慕中使用令牌桶进行限流的时候,如果某一时候请求连接过多,就返回429状态码
响应头部也是以键值对的形式提供的额外信息,类似于请求头部,用于告知客户端有关响应的详细信息。一些常见的响应头部字段包括:
● Content-Type:指定响应主体的媒体类型。
● Access-Control-Allow-Origin: 跨源资源共享(CORS)策略,指示哪些域可以访问资源。
● Content-Length:指定响应主体的长度(字节数)。
● Expires: 响应的过期时间。
● ETag: 响应体的实体标签,用于缓存和条件请求。
● Last-Modified: 资源最后被修改的日期和时间。
● Location:在重定向时指定新的资源位置。
● Set-Cookie:在响应中设置Cookie。
空行(Empty Line)在响应头和响应体之间,表示响应头的结束。而响应体是服务端实际传输的数据,可以是文本、HTML页面、图片、视频等,也可能为空。
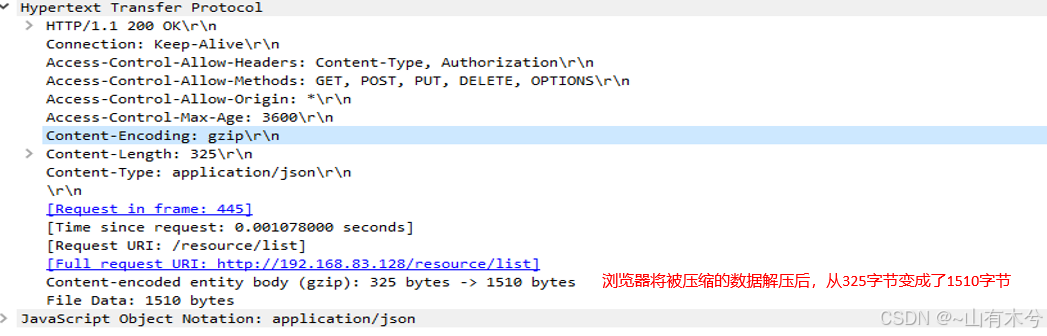
wireshark抓包分析
![image]()
- 状态行返回 HTTP/1.1(协议版本),200(状态码),ok(状态码对于的短语)
- 响应头部,也是以键值对形式保存值的。
Connection: Keep-Alive(表示这是一个长连接,即可以在这个连接上多次请求与响应);Access-Control-Allow-Origin: *(支持跨域访问源,这里的‘*’表示所有源都可访问);Content-Encoding: gzip(表示使用了gzip编码);Content-Length: 325(这个字段表示响应体的数据大小为325字节);Content-Type: application/json(表示响应体的格式为json)
- 响应体可以是多种格式,在这里是json格式,见下图
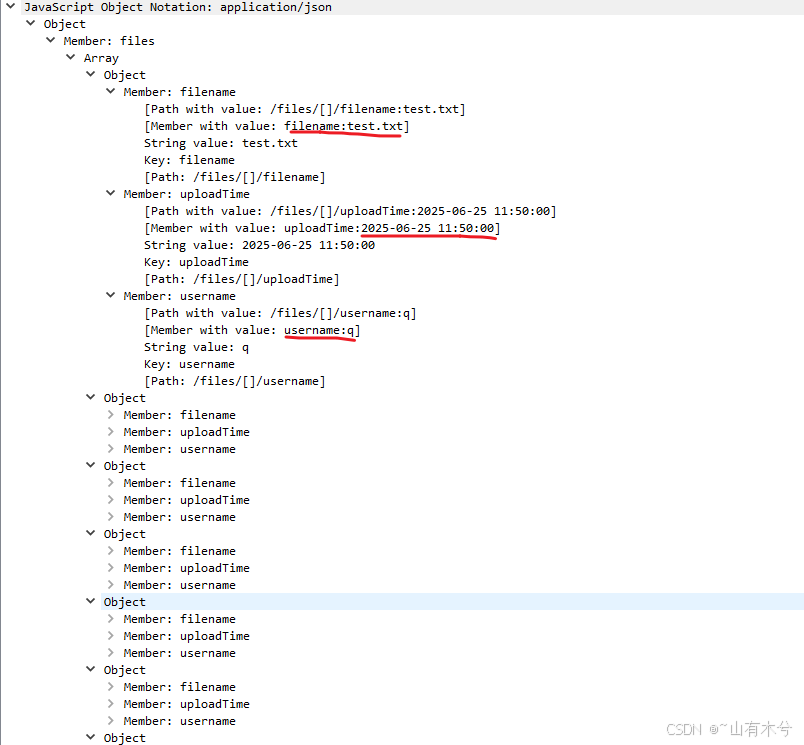
![image]()
这里的一个json文件中有3个值,filename,uploadtime,username;多个json文件构成了一个Array。
代码实现
响应字段是由浏览器解析的,这里我们不需要实现解析的部分。响应是由服务器生成并返回的,所以在这里需要实现HTTP响应报文的生成。
请看代码:
1.设置状态行
1
2
3
4
5
6
7
8
9
| void HttpResponse::setStatusLine(const std::string& version,
HttpStatusCode statusCode,
const std::string& statusMessage)
{
httpVersion_ = version;
statusCode_ = statusCode;
statusMessage_ = statusMessage;
}
|
2.生成响应体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| void HttpResponse::appendToBuffer(muduo::net::Buffer* outputBuf) const
{
char buf[32];
snprintf(buf, sizeof buf, "%s %d ", httpVersion_.c_str(), statusCode_);
outputBuf->append(buf);
outputBuf->append(statusMessage_);
outputBuf->append("\r\n");
if (closeConnection_)
{
outputBuf->append("Connection: close\r\n");
}
else
{
outputBuf->append("Connection: Keep-Alive\r\n");
}
for (const auto& header : headers_)
{
outputBuf->append(header.first);
outputBuf->append(": ");
outputBuf->append(header.second);
outputBuf->append("\r\n");
}
outputBuf->append("\r\n");
outputBuf->append(body_);
}
|
格式化响应之后,通过网络发送响应消息,浏览器解析响应并渲染,一次HTTP请求就完成了。
if (hexo-config('comment') && hexo-config('comment.enable') == true && hexo-config('comment.use')) {
if (hexo-config('comment.use') == "valine") {
@import "./valine.styl"
}
else if (hexo-config('comment.use') == "gitalk") {
@import "./gitalk.styl"
}
else if (hexo-config('comment.use') == "twikoo") {
@import "./twikoo.styl"
}
else if (hexo-config('comment.use') == "waline") {
@import "./waline.styl"
}
}
.comments-container {
display inline-block
width 100%
margin-top var(--component-gap)
.comment-area-title {
width 100%
color var(--text-color-3)
font-size 1.38rem
line-height 2
i {
color var(--text-color-3)
}
+keep-tablet() {
font-size 1.2rem
}
}
.configuration-items-error-tip {
display flex
align-items center
margin-top 1rem
color var(--text-color-3)
font-size 1rem
i {
margin-right 0.3rem
color var(--text-color-3)
font-size 1.2rem
}
}
.comment-plugin-fail {
display none
flex-direction column
align-items center
justify-content space-around
width 100%
padding 2rem
.fail-tip {
color var(--text-color-3)
font-size 1.1rem
}
.reload {
margin-top 1rem
}
}
.comment-plugin-loading {
flex-direction column
padding 1rem
color var(--text-color-3)
.loading-icon {
color var(--text-color-4)
font-size 2rem
}
.load-tip {
margin-top 1rem
color var(--text-color-4)
font-size 1.1rem
}
}
}