

顺序容器
vector(向量容器)
vector是STL容器中的一种常用的容器,和数组类似,由于其大小(size)可变,常用于数组大小不可知的情况下来替代数组。vector也是一种顺序容器,在内存中连续排列,因此可以通过下标快速访问,时间复杂度为O(1)。然而,连续排列也意味着大小固定,数据超过vector的预定值时vector将自动扩容。
以下代码是创建vector,插入元素(push_back),删除元素(pop_back)等的用法。
1 | vector<int> vec; |
在上述代码中,定义了vector<int> vec;这个时候vec的大小是多少呢?这里没有指定开辟多大空间,那么这个vec的大小默认就是0了;那么在上述代码中,频繁的指向插入操作,就会频繁的扩容,涉及到内存中数据的频繁拷贝,效率低;所以一般在定义vector时会预留vector的大小,请看下面代码:
1 | /* |
tips:这里reserve函数在内存中给vec1预留了20大小的内存,但是需要注意的是现在vec1实际的大小为0;如果想访问vec1[0]会报数组越界错误。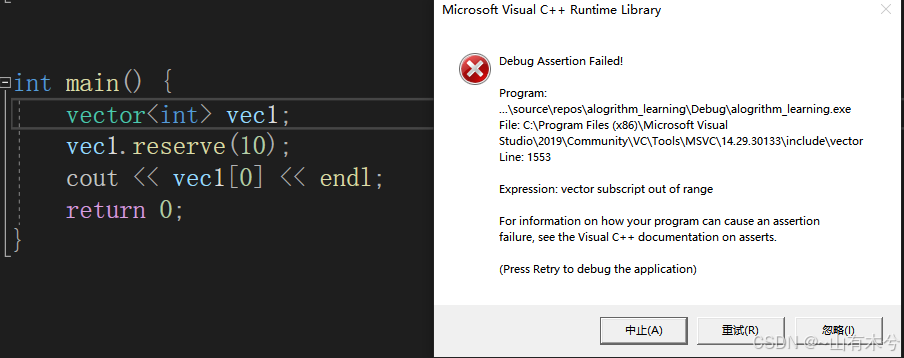
使用迭代器删除和插入元素,这里要防止迭代器失效。关于迭代器失效,可以参考我的另一篇文章
1 | //删除所有偶数,erase()的时间复杂度为o(n) |
vector的扩容原理
在学习过程中,遇到地关于vector扩容有两种说法,一是按照1.5倍扩容,一是按照2倍扩容,下面就通过代码验证一下。
1 |
|
在windows平台下执行,打印结果为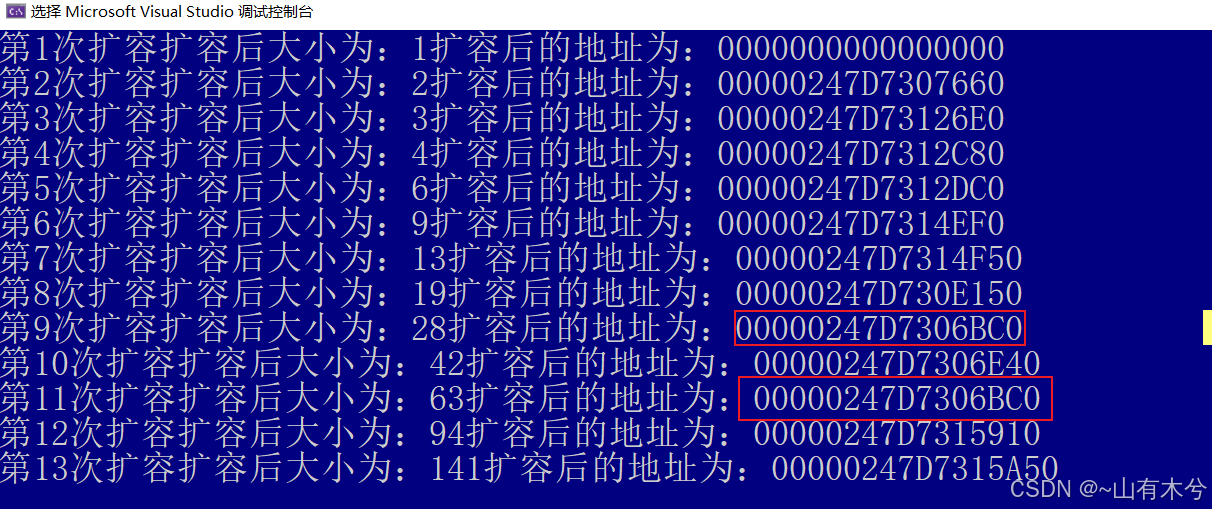
可以看到,在该平台下,是按照
1 → 2 (11.5=1.5,取2)
2 → 3 (21.5=3,取3)
3 → 4 (31.5=4.5,取4)
4 → 6 (41.5=6,取6)
6 → 9 (61.5=9,取9)
9 → 13 (91.5=13.5,取13)
13 → 19 (131.5=19.5,取19)
19 → 28 (191.5=28.5,取28)
28 → 42 (281.5=42,取42)
42 → 63 (421.5=63,取63)
63 → 94 (631.5=94.5,取94)
94 → 141 (941.5=141,取141)
可以看到,如果采用的是1.5倍扩容方法,在这里我们需要申请128大小的空间,而最后申请的空间是141;并且前几次申请的空间1+2+3+4+6+9+13+19+28+42+63+94=284>128,如果前面申请的空间是连续的,也就可以直接复用前面的内存了
比如说,在上图中,第9次扩容和第11次扩容的地址就是一样的(表明旧内存块在扩容后被释放,新分配的内存可能重新利用之前的地址。这说明1.5倍扩容在内存回收和复用上有优势。)
采用1.5倍扩容的缺点也比较明显,也就是涉及到多次的扩容操作,申请128大小的需要扩容13次;而采用2倍扩容方法只需要。。。
在linux平台下执行,打印结果为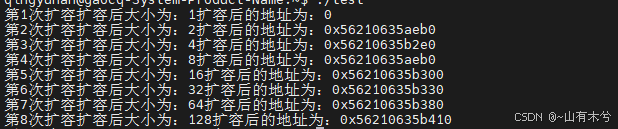
并且前几次申请的空间1+2+4+8+16+32+64=127<128,不可以完整的复用前面申请的内存空间
(但是这里第2次和第4次扩容后的起始地址是一样的,暂时还没了解清楚)
【C++ Primer】 erase和insert返回的迭代器位置总结
详解C++STL容器系列(一)—— vector的详细用法和底层原理这篇关于vector的讲解还挺不错的,大家可以参考
deque(双端队列容器)
deque即(double-ended queue)双端队列容器,支持o(1)时间复杂度内在头部和尾部插入和删除元素;deque没有容量的概念,而是动态地以分段连续空间组合而成,随时可以增加一段新的空间并连接起来。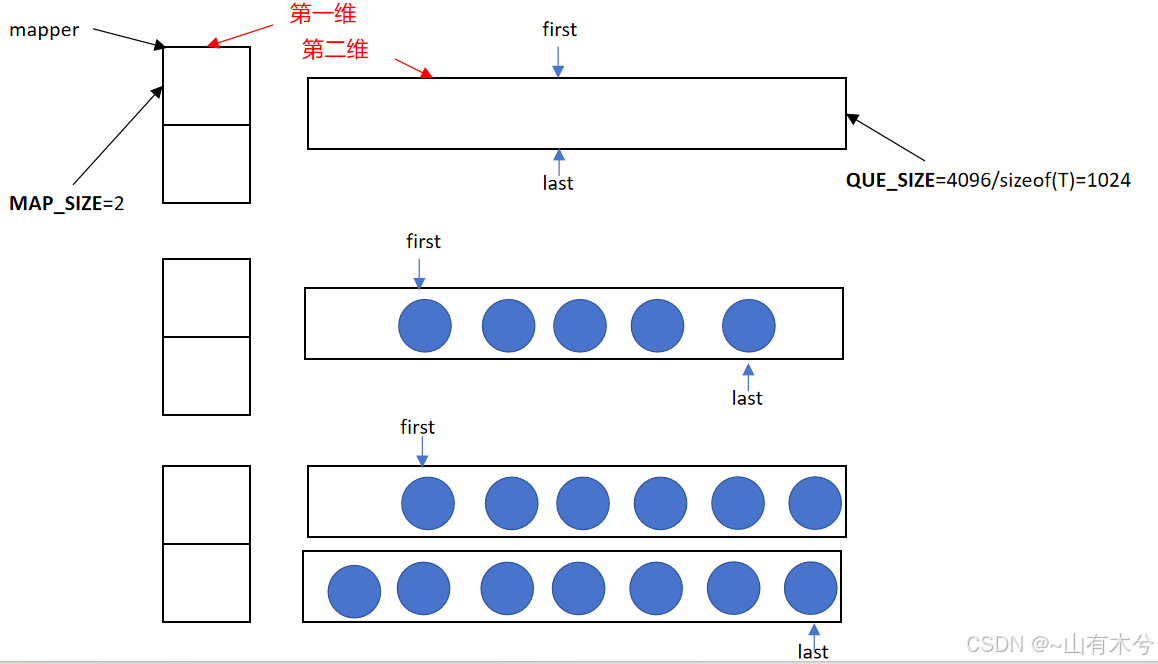
初始时,first和last指针位于二维数组的中间位置(感觉这里类似两个vector拼接而成的结构)。当从尾部插入元素时,last指针向后移动;当从头部插入元素时,first指针向前移动。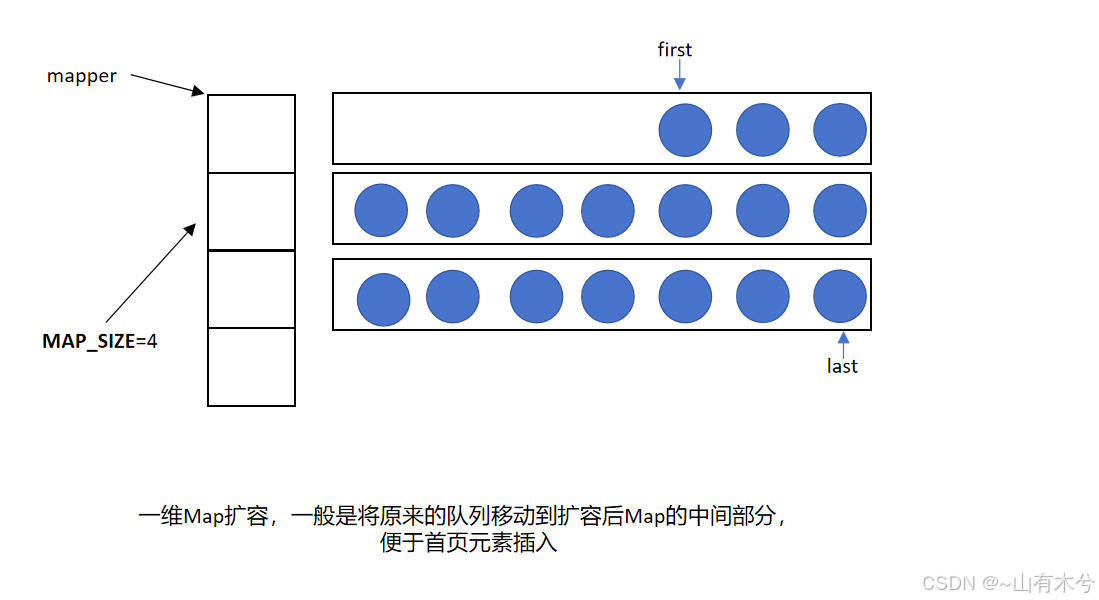
增加元素操作:
deq.push_back(20);从末尾添加元素,时间复杂度o(1)
deq.push_front(10);从首部添加元素,时间复杂度o(1)
deq.insert(it,30);it指向的位置添加元素
删除操作:
deq.pop_back(20);从末尾删除元素,时间复杂度o(1)
deq.pop_front(10);从首部删除元素,时间复杂度o(1)
deq.erase(it);it指向的位置删除元素
查询操作:
iterator(连续的insert和erase一定要考虑迭代器失效问题)
更多关于deque的理解,请参考详解STL中的deque
list(链表容器)
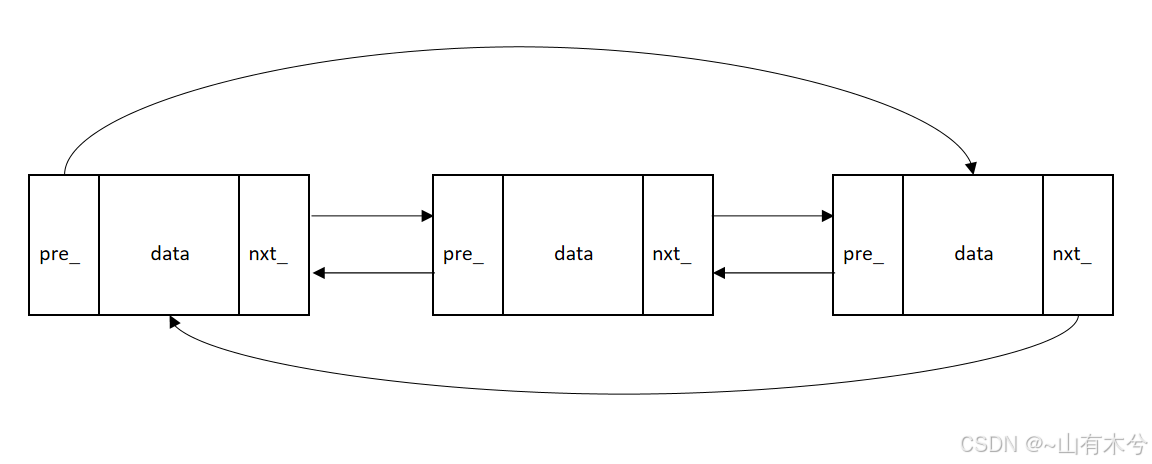
模板类list是一个容器,list是由双向链表来实现的,每个节点存储1个元素。list支持前后两种移动方向。
优势 :任何位置执行插入和删除动作都非常快。
缺点 :不支持随机存取,查找某个元素的效率较低。
小结
deque和list,比vector容器多出来的增加删除的接口为:push_front()和pop_front()。
vector特点:动态数组,内存是连续的,以2倍的方式进行扩容(linux平台下是2倍,在windoes平台下是1.5倍)
deque特点:动态开辟的二维数组空间,第二维是固定长度的数组空间,扩容的时候(第一维的数组进行2倍扩容,再把原来的第二维数组放到新扩容的第一维数组的中间部分,便于支持deque前后的插入与删除)
deque底层是否是连续的?
答:并不是,deque的每一个第二维数组都是连续的,整体来看是分段连续的。第一维指向不同的二维连续区域(deque是动态开辟的二维数组)
vector和deque的区别
- 底层数据结构:vector是动态数组,deque是动态二维数组
- vector的中间和首部插入元素时间复杂度为o(n),末尾插入时间复杂度为o(1);deque的首部和末尾插入时间复杂度为o(1),中间插入的时间复杂度为o(n)
- 内存的使用效率:vector的内存使用效率低,原因是vector需要一片连续的内存空间,当发生扩容时,原来内存上的已存在的数据需要复制到新开辟的内存空间中去;而deque不要求整片连续的空间,只要求分段连续就可以,当发生扩容的时候,也只是第一维发生扩容,(在第二维不会发生复制,应该还是保留在原来的内存去,只需要开辟额外需要的内存就行?不如说第一维度从2扩容到4,第二维只需要新开辟2个连续的内存空间就好,加上原来的两个内存空间上的数据,尚未实验验证)
- 在中间进行insert和erase,vector的效率会更高一些。虽然两者的时间复杂度都为o(n),但是由于vector是一整片连续的内存空间,由于cpu的缓存机制,即时间局部性和空间局部性原理,vector的效率必然会更高一些。
空间局部性(Spatial Locality):
如果程序访问了某个内存地址,很可能很快会访问其附近的内存。
vector 的优势:元素在内存中是连续的,CPU 会预加载相邻元素到缓存(缓存行通常为 64 字节),后续访问命中缓存,速度极快。时间局部性(Temporal Locality): 最近访问的数据很可能被再次访问。
vector的优势:移动元素时,被操作的元素在内存中是连续的,缓存命中率高。
vector和list的区别
类比数组和链表的区别
底层数据结构:数组、双向循环链表
时间复杂度
1.vector的增加、删除时间复杂度为o(n),下标随机访问o(1),查找特定元素复杂度o(n);
2.list的增加、删除(不考虑查找待删除元素)时间复杂度为o(1),查询操作为o(n);
容器适配器
容器适配器包括statck、queue、priority_queue。
1.适配器底层没有自己的数据结构,它是另外一个容器的封装,它的方法全由底层依赖的容器实现的。
2.没有实现自己的迭代器(不可通过迭代器访问)
statck的源码截图如下:
stack的简单框架如下:
1 | template<typename T,typename Container=deque<T>> |
容器适配器的操作方法
statck:
- push入栈
- pop出栈
- top查看栈顶元素
- empty判断栈空
- size返回元素个数
queue:
- push入队
- pop出队
- front查看队头元素
- back查看队尾元素
- empty判断队空
- size返回元素个数
priority_queue:
- push入队
- pop出队
- top查看队头元素
- empty判断对空
- size返回元素个数
1 | int main() |
底层容器
statck依赖deque、queue也依赖deque容器、priority_queue依赖vector容器。
stack和queue为什么依赖deque容器?
- vector的初始内存使用效率太低了,需要从1-2-4-8频繁扩容;而deque的第二维度默认开辟空间
4096/sizeof(int)=1024字节大小内存 - 对于queue来说,需要实现先进先出,即需要实现头删尾插,而deque的首尾操作的时间复杂度为o(1)
- vector需要大片的连续内存,而deque只需要分段连续的内存;对于大量数据存储,deque的内存利用率更好一些(随着程序的运行,会产生大量的内存碎片,此时要找一块连续且空间较大的内存相对较复杂)。
priority_queue为什么依赖vector容器?
priority_queue采用堆的存储,底层默认把数据组织成大根堆结构(也存在小根堆),要求在一片连续的内存空间。
核心概念:堆是一颗完全二叉树,它的特点是可以用一维数组来储存。
对于一个序号从0开始的堆结构
对于第idx个节点
父节点序号:(idx-1)/2
左子节点顺序: idx* 2+1
右子节点顺序: idx* 2+2
对于堆结构来说,采用数组存储方式是因为父子节点与其下标之间存在联系。根据存储元素在数组中的下标,可以计算得到父节点,左子节点,右子节点的下标,然后分别得到对应的值。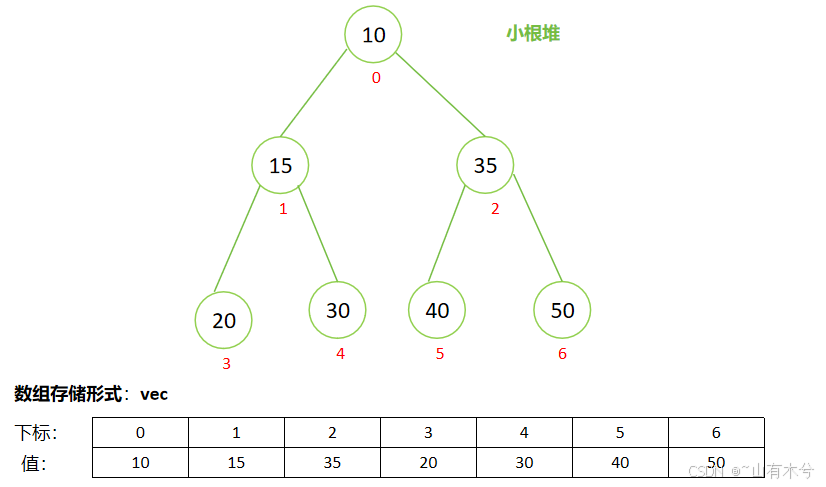
如确定节点2的父节点、左子节点、右字节点的值步骤如下:
idx=2
父节点值:vec[(idx-1)/2]=vec[0]=10
左子节点:vec[idx2+1]=vec[5]=40
右子节点:vec[idx2+1]=vec[6]=50
总结:由于 std::vector 将元素存储在连续的内存块中,使得通过下标 i 访问元素 vec[i] 变得极其高效。vec[i] 的地址只需起始地址加上 i 乘以元素大小的偏移量 (start_address + i * sizeof(element))。这种 O(1) 复杂度的随机访问能力,是堆能够利用简单的下标计算(如 父节点=(i-1)/2, 左孩子=2i+1, 右孩子=2i+2) 在数组中高效模拟树形结构并快速定位父子节点的根本前提。非连续存储的数据结构(如链表)无法进行这种直接的下标计算和访问。
关联容器
有序关联容器,底层为红黑树,增删查的时间复杂度为o(log2(n)),2为底数
- set (集合 key)
- multiset (多重集合)
- map (映射表 [key,value])
- multimap (多重映射表)
无序关联容器,底层为链式哈希表 增删查的时间复杂度为o(1)
- unordered_set
- unordered_multiset
- unordered_map
- unordered_multimap
常用方法:
增加:insert(val)
遍历:iterator搜索,调用find成员方法
删除:erase(key) 、erase(iterator)
无序容器
unordered_set的常见方法:
1 | unordered_set<int> set1;//元素不可重复 |
unordered_map的常见方法:
1 | unordered_map<int, string > map1; //不允许key重复 |
场景应用:
统计所有数据的出现次数,打印出现频次大于1的数的值及其出现频次:一般使用unordered_map
将给定的大量数据进行去重,仅打印出现1次的数:一般使用unordered_set
有序容器
有序容器的基本操作与无序容器的基本操作一致,略有不同的是,有序容器内部会保持元素的顺序(默认是升序)。
1 | class student |
这里我们自定义了一个学生类容器放到set有序集合容器中,报错了

这是因为在自定义的student类中并没有实现小于运算符重载,代码修改如下
1 | class student |
打印结果为:
map容器
1 | map<int,student> stuMap;//如果要使用自定义的类student定义map,要求自定义的类存在默认构造函数 |
这里对应STL容器的总结还不够全面,主要是在我学习过程中遇到的一些知识点进行记录。后序学习过程中遇到了会继续更新。